
Problem Statement
|
Modified National Institute of Standards and Technology (MNIST) has released a dataset containing 42,000 images of hand written digits along with the number in the image (label). We have to create an algorithm that can classify these images according to the number in the image. They have also released a test dataset of 28,000 images to predict the correct digits in them.
|
Experiment
|
There are various ways to solve this problem like Support Vector Machines (SVM), Fuzzy Logic, Decision Trees or Nearest Neighbour. But, here I am using the Artificial Neural Network (ANN) method to classify the digits.
In ANN, we consider the classification problem as a function approximation problem, where the input to the function is a fixed sized array having pixel values and the output is probability of having that number in given image for each digit. We assume that this function is a non-linear function and hence we use ANN based approach. For this project, I have considered a very simple fully connected neural network having an input layer of size 512 and two hidden layers of size 512. Output layer will have size 10 as we have digits from 0 to 9. Following image shows the pictorial view the network architecture. Green, Blue, Red are the input, hidden and output layers respectively. 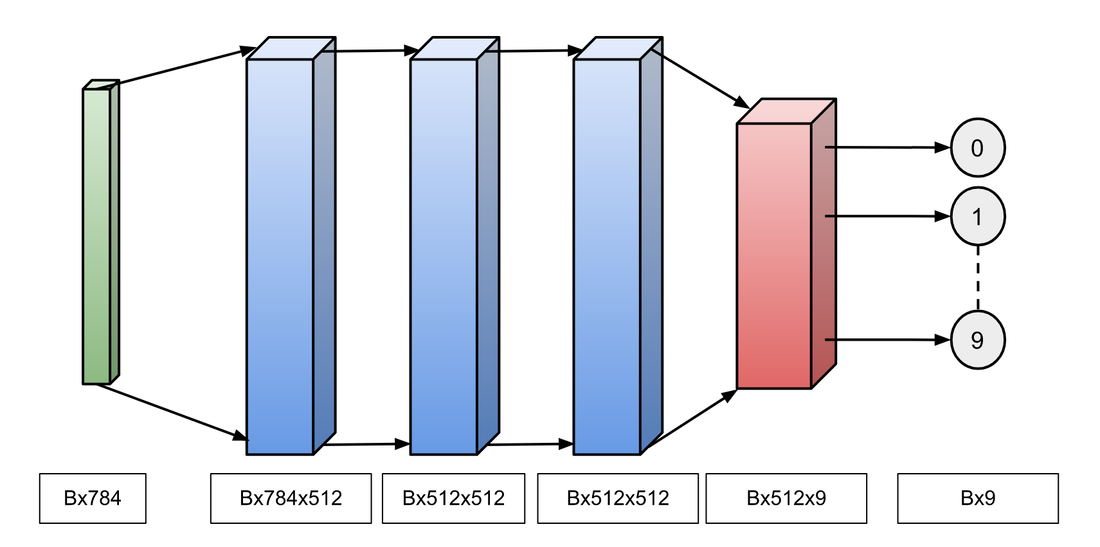
Network Structure for Digits Classification with B as Batch Size
|
Results
|
The network simply tries to convert a high dimensional input to lower dimensional data in a latent space and the data in this space is called features. These features are representatives of the corresponding images. These features are then provided to a classifier to classify the data.
I have considered that three hidden layers are used to find the features from the image in a 512 dimensional space. Then the output layers behave like a classifier. And I have used a sparse softmax cross-entropy function for loss. A very simple visualisation of these features in 2D space can be achieved by t-Stochastic Neighbour Embedding (t-SNE) method. I have also added the results of this visualisation. |
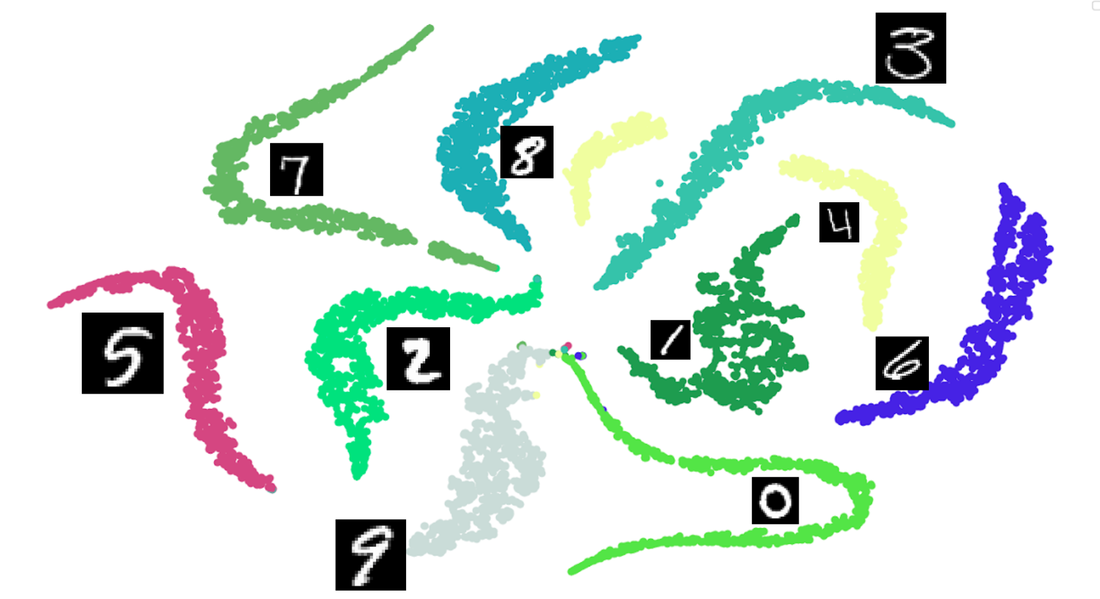
t-SNE plot for MNIST digits
