
Problem Statement
|
Aim: Locomotion of Turtlebot in an indoor scenario using Reinforcement Learning.
Training a Reinforcement Learning algorithm on real robot is not an efficient way as the system is costly, many more samples or epochs of training aren't affordable and may lead to harmful situations. Pros of Simulation: We can train millions of episodes for the reinforcement learning agent in simulation. Do not have to pay any cost for system or damage of hardware. (i.e. wear and tear of robot) No need to worry about injuries or harmful situations. |
Environment Modelling

Comparison of Simulation vs Real Environment

Gazebo Environment

|

|
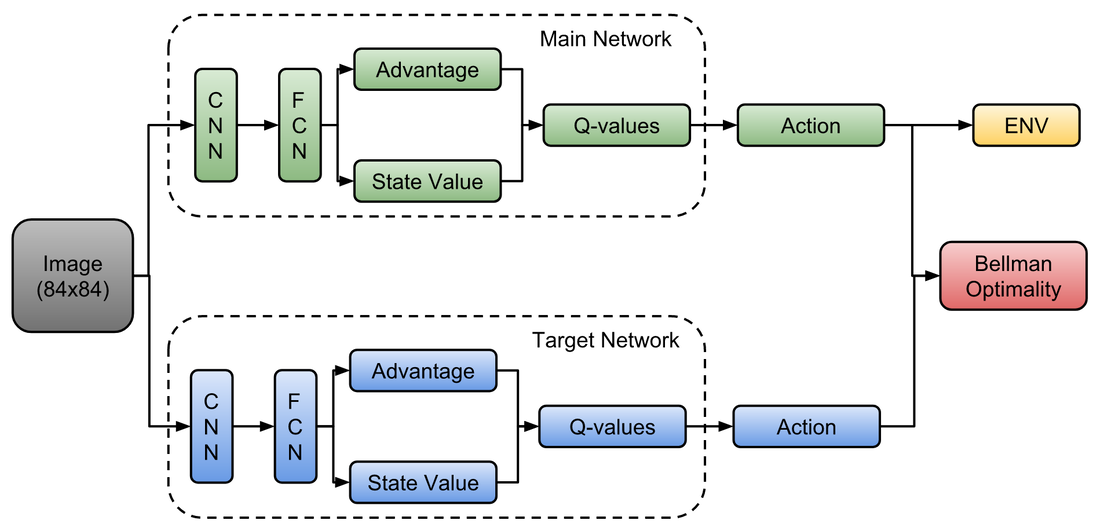
Dueling Double DQN
We have used a Dueling Double Deep Q-Network to train our agent in Gazebo Simulation. Use of Advantage and State value improves the training speed. And use of double networks (i.e. Main Network and Target Network) makes the training more stable as target network is updated after a particular number of episodes.
We have used a Kinect on robot to get the RGB images of the world which are used as input to the network and horizontal laser scans to detect if the robot has collided with wall or not in Gazebo only. While testing, I have used only camera to perceive the world.
We have used a Kinect on robot to get the RGB images of the world which are used as input to the network and horizontal laser scans to detect if the robot has collided with wall or not in Gazebo only. While testing, I have used only camera to perceive the world.
Going from Simulation to Real World
|
Training an agent in Gazebo Simulation and taking the exact same policy to real world will lead to failure. There are many reasons behind this. We also faced this challenge. First major problem is that the agent will get over-fitted with the path it has learnt to reach the goal. So, in real world even slight change in the starting position will lead to a collision with the wall. Also, change in lighting conditions affect the images actions decided by DD-DQN.
To tackle this problems, we basically have allocated random positions and orientations to robot in each episode. So, the robot will try to learn how to go to goal instead of just overfitting the path. It will also explore lots of states which may not be explored if we start from a fix initial position. We also have altered the goal positions by smaller values in x,y- plane. For lightning conditions, we got lucky that CMU has a fixed lightning conditions which doesn't get affected by outside environment. But the solution to this problem is having random light source intensities during training of each episode. These are the major changes done to transfer the policy from simulation to real world during training along with some changes in reward function. |
