
|
This is a simple Q-learning problem of a grid world. I am writing this for the beginners in Reinforcement learning. Learning Q-values forms the basis to understand learning process of any agent. So the below image shows the world for the agent with circle as goal, dark square as obstacle and cross as dead end. 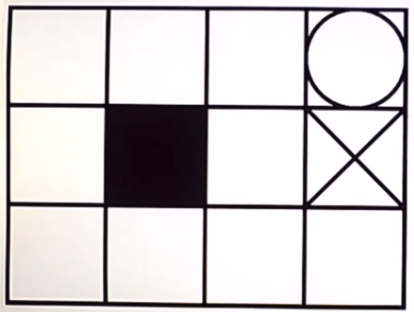  Reaching the goal position gives +1 reward to agent. Every step gives -0.04 reward. Q-value is the expected value for every possible action in that state. This is stored in every grid. Then we will take the highest value from those Q-values and will take that action. This will lead to Q-learning in Grid world. Q-learning as we are finding the Q-function. Below image shows the optimal policy obtained by simple logic:   These are the initial Q-values. 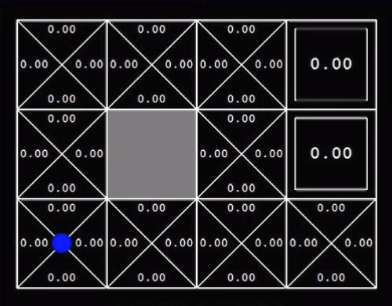 These are the Q-values after training of certain episodes. 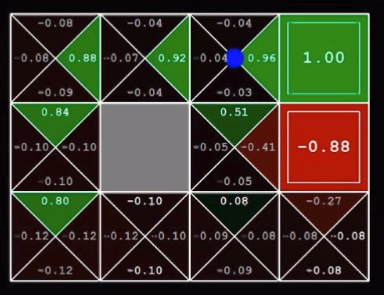 Below is the algorithm for Q-learning.  I have trained an agent in this grid world. The grid world is designed using pygame in python. Q- learning algorithm is implemented in python. To understand the code thoroughly, check the github link.
Grid_World_Env.py is the grid world developed using pygame. And grid_world_q_learning.py is the agent which is trained using python.
0 Comments
Q-Learning: In reinforcement learning, we want to obtain a function Q(s,a) that predicts best action a in state s in order to maximize a cumulative reward.  This function can be estimated using Q-learning, which iteratively updates Q(s,a) using the Bellman Equation. 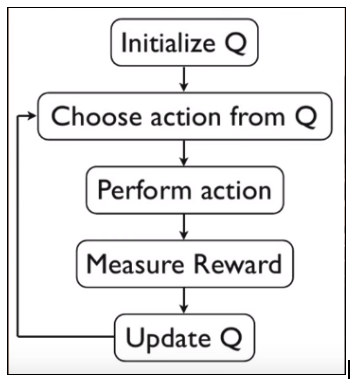 Above image is the algorithm for Q-learning. Initialization of state and action matrix should be random.
But, while doing a Q-learning, we have to explore everything to find the best action value function. The reason is explained below: For ex. Suppose there are two doors to go through for an agent. One door gives +1 reward for passing through it and another gives 0. So as per Q-function the agent will always try to go through first door to get +1 reward. But we don’t know the rewards for the states after that door. It might happen that passing through second door will result into +100 reward at end of episode and passing through first will only lead to +35. So, it is important to take some random actions at initial stage and as the episodes increases we will try to take greedy actions (suggested by Q-function) |
AuthorVinit is a computer scientist and roboticist. His research focuses on making machines intelligent. Categories
All

|
