
|
Most important difference in between them is as follows: Q-Learning: Off-Policy Learning Sarsa: On-Policy Learning 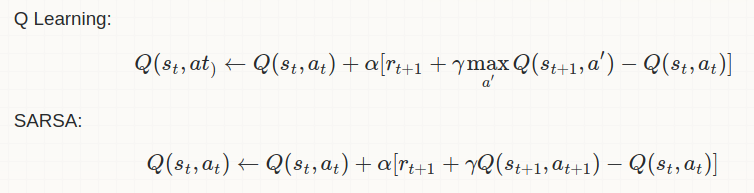 So, as per the above mathematical equations SARSA uses the action value function (Q-value) for the action which has been taken in the step and hence it is an on-policy learning. While Q-learning, explores action values for all possible actions in given state and selects the one having the maximum action value. This clearly indicates that Q-Learning is an off policy learning.
Q-learning has the following advantages and disadvantages compared to SARSA:
If your goal is to train an optimal agent in simulation, or in a low-cost and fast-iterating environment, then Q-learning is a good choice, due to the first point (learning optimal policy directly). If your agent learns online, and you care about rewards gained whilst learning, then SARSA may be a better choice.
1 Comment
Experience replays are generally used for off policy learning. After taking some random actions from the action space, the tuple <s(t) ,a ,r ,s(t+1)> is stored in the memory. All such tuples are used in the end to train the algorithm by learning it multiple times. On-policy learning requires on the spot update of policy and so it can't use experience replay. TD(lambda), actor-critic, SARSA are the examples of on-policy learning. While A3C can be used as either on-policy or off-policy. 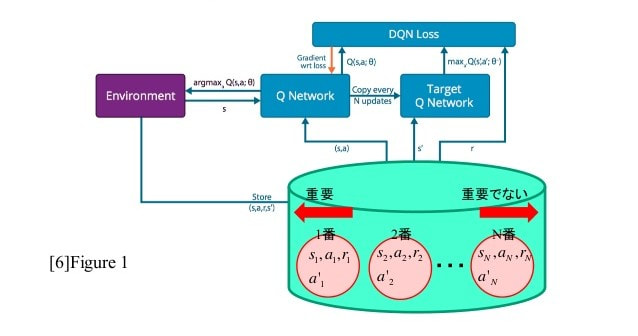 The above figure shows the pseudo code for experience replay reinforcement learning. All the experiences are stored in a database. Then these experiences are used to train the Q-values using neural network. Multi-step Learning It is simply a look forward in the training. n-step MC, TD (lambda), n-step A3C are some examples of it. It simply starts from one state and takes 'n' actions to receive further states and rewards. Then these rewards are used to get the discounted rewards or returns and then the policy is updated using them. This method also requires the storage of n-tuples in the memory. But there is no multiple times learning using these tuples. This gives an explicit exploration to the algorithm. As the policy used to explore will explore various states, action pairs and will give good results.
Reinforcement Learning involves two types of value iterations. 1) Value Iteration V(s) and 2) Policy Iteration Q(s,a). Also V(s) is called the state value function and Q(s,a) is the action value function. Value iteration finds how good it is to be in that particular state while the action value function evaluates that how good will it be to take a given action from the given state. This is an important explanation for the further topic. 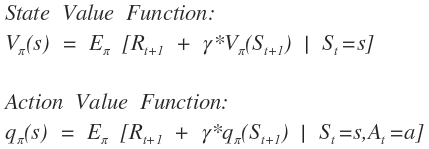 Let us consider a game of 4x3 grid where the agent starts at a fix location (bottom left corner) with a fixed goal (top right corner). Here we already knew the probability to reach certain new state with given initial state and action taken. So, we already know the dynamics of the game, which means we are relying on the given model of game. So this is example of Model-Based RL. But let us suppose an autonomous car which is driven by RL network, then there won't be an exact dynamics. Just like atari games, can be played using the images of the screen. So, we cannot predict the new state even if know the action taken. Such environments are known as Model-Free Environment. Such environment is called a black box. We can use any of the two methods mentioned in first passage to find an optimal policy for model-based RL. As the action value function can be found out using environment dynamics/model and state value function. Both will work similarly. But in case of Model-Free RL, we cannot use state value function as it will indicate any significance. Action value function will be the most important to calculate in such situation. Because here we do not know which action will lead to which state and what will be the reward. So, it is needed to explore most of the actions and states. In such cases, Action value function will tell us about the value associated with each state and each action. 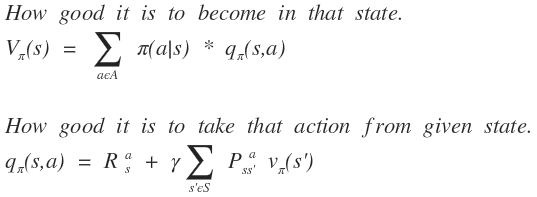 State value function can found by using Action value function and model of environment. But in Model-Free environment, policy pi (a | s) is unknown and state value iteration will not be effective to find the policy. The reason behind this is we cannot obtain action-value function as we don't have any idea that which action will lead to which state. It means, we have complete knowledge about which state will be better in future, but we have no clue which action should be selected to reach that state.
On the opposite, if we choose action value function, we knew that which action will be the best to choose for a given state from the action space and hence we can find the optimal policy using it in Model-Free environment. There may be many concepts or definitions of reinforcement learning. Some say it is an area of Machine Learning inspired by behaviourist psychology. A branch of AI that deals with software agents to automatically determine the ideal behaviour within a specific context, in order to maximize its performance. According to KDnuggets, "Reinforcement Learning is concerned with the problem of finding suitable actions to take in a given situation in order to maximize a reward."  But I will give you a very simple example of Reinforcement learning which will make you understand its concept. When you learn to ride a motorcycle is the best example of RL. From the state to switch on the bike, to control the balance, to take turn and till the state to reach destination, every stage is a state space for the human agent and doing it properly gives a positive reward of being fit. Taking a wrong step in state will lead to an accident. Injury will be the negative reward.
After riding the bike for few months, we gather a lot of experience to drive in a harsh traffic or in crowded place. On this basis, our brain having numerous neurons chooses the optimal policy using the sensation of ears and vision. How brilliant our brain is!!! I was driving a bike and a car went across me. I slowed down my bike and waited the car to pass. As the car was half passed I raised the speed to go ahead. This needed the a proper guess of speed of the car, time it will take to cross and speed of my bike. All this comes with an experience. And you will master the driving after a lot of experience. Hence it is a very clear example of RL. Collaboration indicates work of a team to achieve certain with an individual task for everyone. Collaboration doesn’t require sharing of information amongst each other. Here the success doesn’t depend on everyone. Cooperative policy indicates the team work with everyone working towards the goal and the results depend on the struggle of complete team. Let’s understand it with an example! Suppose, there is a house which has to emptied. Now, there are three persons in house. If each person takes each item out of house without having any conversation in between them then it is a Collaborative Policy. No one knows what others thinking or what strategy they have in mind. But task will be accomplished. On the other hand, if there is a sofa in house. Then these three persons will have to lift the sofa together and will have to take it out. So, this will require a lot coordination among them. They must communicate amongst themselves about their policy to achieve the goal. This is called a Cooperative Policy.  Cooperative Policy This is a simple Q-learning problem of a grid world. I am writing this for the beginners in Reinforcement learning. Learning Q-values forms the basis to understand learning process of any agent. So the below image shows the world for the agent with circle as goal, dark square as obstacle and cross as dead end. 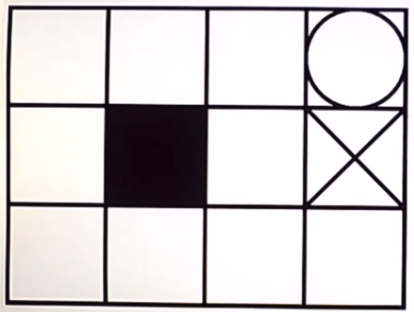  Reaching the goal position gives +1 reward to agent. Every step gives -0.04 reward. Q-value is the expected value for every possible action in that state. This is stored in every grid. Then we will take the highest value from those Q-values and will take that action. This will lead to Q-learning in Grid world. Q-learning as we are finding the Q-function. Below image shows the optimal policy obtained by simple logic:   These are the initial Q-values. 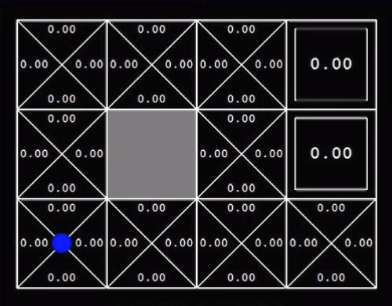 These are the Q-values after training of certain episodes. 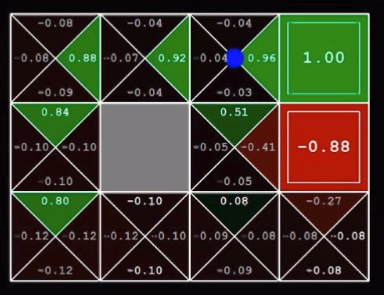 Below is the algorithm for Q-learning.  I have trained an agent in this grid world. The grid world is designed using pygame in python. Q- learning algorithm is implemented in python. To understand the code thoroughly, check the github link.
Grid_World_Env.py is the grid world developed using pygame. And grid_world_q_learning.py is the agent which is trained using python. Q-Learning: In reinforcement learning, we want to obtain a function Q(s,a) that predicts best action a in state s in order to maximize a cumulative reward.  This function can be estimated using Q-learning, which iteratively updates Q(s,a) using the Bellman Equation. 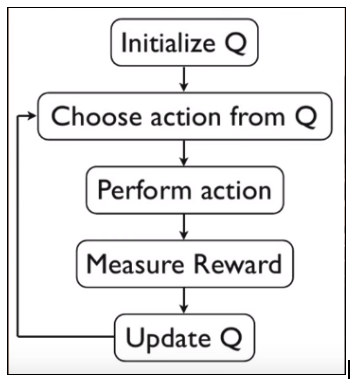 Above image is the algorithm for Q-learning. Initialization of state and action matrix should be random.
But, while doing a Q-learning, we have to explore everything to find the best action value function. The reason is explained below: For ex. Suppose there are two doors to go through for an agent. One door gives +1 reward for passing through it and another gives 0. So as per Q-function the agent will always try to go through first door to get +1 reward. But we don’t know the rewards for the states after that door. It might happen that passing through second door will result into +100 reward at end of episode and passing through first will only lead to +35. So, it is important to take some random actions at initial stage and as the episodes increases we will try to take greedy actions (suggested by Q-function) |
AuthorVinit is a computer scientist and roboticist. His research focuses on making machines intelligent. Categories
All

|
