
|
Most important difference in between them is as follows: Q-Learning: Off-Policy Learning Sarsa: On-Policy Learning 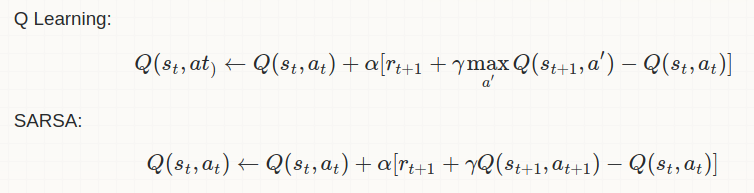 So, as per the above mathematical equations SARSA uses the action value function (Q-value) for the action which has been taken in the step and hence it is an on-policy learning. While Q-learning, explores action values for all possible actions in given state and selects the one having the maximum action value. This clearly indicates that Q-Learning is an off policy learning.
Q-learning has the following advantages and disadvantages compared to SARSA:
If your goal is to train an optimal agent in simulation, or in a low-cost and fast-iterating environment, then Q-learning is a good choice, due to the first point (learning optimal policy directly). If your agent learns online, and you care about rewards gained whilst learning, then SARSA may be a better choice.
1 Comment
Arun
4/6/2020 03:30:51 pm
Why dont you write more such articles? They seem very easy to understand and quite useful Leave a Reply. |
AuthorVinit is a computer scientist and roboticist. His research focuses on making machines intelligent. Categories
All

|
